本文介绍DMA的基础知识
本文转自 http://blog.csdn.net/kafeiflynn/article/details/6665743
总线地址
DMA的每次数据传送(至少)需要一个内存缓冲区,它包含硬件设备要读出或写入的数据。一般而言,启动一次数据传送前,设备驱动程序必须确保DMA电路可以直接访问RAM内存单元。
现已区分三类存储器地址:逻辑地址、线性地址以及物理地址,前两个在CPU内部使用,最后一个是CPU从物理上驱动数据总线所用的存储器地址。但还有第四种存储器地址,称为总线地址(bus address),它是除CPU之外的硬件设备驱动数据总线时所用的存储器地址。
从根本上说,内核为什么应该关心总线地址呢?这是因为在DMA操作中,数据传送不需要CPU的参与;I/O设备和DMA电路直接驱动数据总线。因此,当内核开始DMA操作时,必须把所涉及的内存缓冲区总线地址或写入DMA适当的I/O端口,或写入I/O设备适当的I/O端口。
在80x86体系结构中,总线地址与物理地址一致。然而,其他体系结构如Sun SPARC和HP Alpha都包括一个I/O存储器管理单元(IO-MMU)硬件电路,它类似微处理器分页单元,将物理地址映射为总线地址。使用DMA的所有I/O驱动程序在启动一次数据传送前必须设置好IO-MMU。
不同的总线具有不同的总线地址大小,ISA的总线地址是24位长,因此在80x86体系结构中,可在物理内存的低16MB中完成DMA传送—-这就是为什么DMA使用的内存缓冲区分配在ZONE_DMA内存区中(设置了GFP_DMA标志)。原来的PCI标准定义了32位总线地址;但是,一些PCI硬件设备最初是为ISA总线设计的,因此它们仍然访问不了物理地址0x00ffffff以上的RAM内存单元。新的PCI-X标准采用64位的总线地址并允许DMA电路可以直接寻址更高的内存。
在Linux中,数据类型dma_addr_t代表一个通用的总线地址。在80x86体系结构中,dma_addr_t对应一个32位长的整数,除非内核支持PAE,在这种情况下,dma_addr_t代表一个64位整数。
pci_set_dma_mask()和dma_set_mask()辅助函数用于检查总线是否可以接收给定大小的总线地址(mask),如果可以,则通知总线层给定的外围设备将使用该大小的总线地址。
高速缓存的一致性
系统体系结构没有必要在硬件级为硬件高速缓存与DMA电路之间提供一个一致性协议,因此,执行DMA映射操作时,DMA辅助函数必须考虑硬件高速缓存。Why?假设设备驱动把一些数据填充到内存缓冲区中,然后立刻命令硬件设备利用DMA传送方式读取该数据。如果DMA访问这些物理RAM内存单元,而相应的硬件高速缓存行(CPU与RAM之间)的内容还没有写入RAM,则硬件设备读取的就是内存缓冲区中的旧值。
设备驱动开发人员可采用2种方法来处理DMA缓冲区,即两种DMA映射类型中进行选择:
- 一致性DMA映射
CPU在RAM内存单元上所执行的每个写操作对硬件设备而言都是立即可见的。反之也一样。 - 流式DMA映射
这种映射方式,设备驱动程序必须注意小心高速缓存一致性问题,这可以使用适当的同步辅助函数来解决,也称为“异步的”
在80x86体系结构中使用DMA,不存在高速缓存一致性问题,因为设备驱动程序本身会“窥探”所访问的硬件高速缓存。因此80x86体系结构中为硬件设备所设计的驱动程序会从前述的两种DMA映射方式中选择一个:它们二者在本质上是等价的。
而在MIPS、SPARC以及PowerPC的一些模型体系中,硬件设备通常不窥探硬件高速缓存,因而就会产生高速缓存一致性问题。
总的来讲,为与体系结构无关的驱动程序选择一个合适的DMA映射方式是很重要的。
一般来说,如果CPU和DMA处理器以不可预知的方式去访问一个缓冲区,那么必须强制使用一致性DMA映射方式(如,SCSI适配器的command数据结构的缓冲区)。其他情形下,流式DMA映射方式更可取,因为在一些体系结构中处理一致性DMA映射是很麻烦的,并可能导致更低的系统性能。
- 一致性DMA映射的辅助函数
通常,设备驱动程序在初始化阶段会分配内存缓冲区并建立一致性DMA映射;在卸载时释放映射和缓冲区。为分配内存缓冲区和建立一致性DMA映射,内核提供了依赖体系结构的pci_alloc_consistent()和dma_alloc_coherent()两个函数。它们均返回新缓冲区的线性地址和总线地址。在80x86体系结构中,它们返回新缓冲区的线性地址和物理地址。为了释放映射和缓冲区,内核提供了pci_free_consistent()和dma_free_coherent()两个函数。 - 流式DMA映射的辅助函数
流式DMA映射的内存缓冲区通常在数据传送之前被映射,在传送之后被取消映射。也有可能在几次DMA传送过程中保持相同的映射,但是在这种情况下,设备驱动开发人员必须知道位于内存和外围设备之间的硬件高速缓存。
为了启动一次流式DMA数据传送,驱动程序必须首先利用分区页框分配器或通用内存分配器来动态地分配内存缓冲区。然后驱动程序调用pci_map_single()或者dma_map_single()建立流式DMA映射,这两个函数接收缓冲区的线性地址作为其参数并返回相应的总线地址。为了释放该映射,驱动程序调用相应的pci_unmap_single()或dma_unmap_single()函数。
为避免高速缓存一致性问题,驱动程序在开始从RAM到设备的DMA数据传送之前,如果有必要,应该调用pci_dma_sync_single_for_device()或dma_sync_single_for_device()刷新与DMA缓冲区对应的高速缓存行。同样的,从设备到RAM的一次DMA数据传送完成之前设备驱动程序是不可以访问内存缓冲区的:相反,如果有必要,在读缓冲区之前,驱动程序应该调用pci_dma_sync_single_for_cpu()或dma_sync_single_for_cpu()使相应的硬件高速缓存行无效。在80x86体系结构中,上述函数几乎不做任何事情,因为硬件高速缓存和DMA之间的一致性是由硬件来维护的。
即使是高端内存的缓冲区也可以用于DMA传送;开发人员使用pci_map_page()或dma_map_page()函数,给其传递的参数为缓冲区所在页的描述符地址和页中缓冲区的偏移地址。相应地,为了释放高端内存缓冲区的映射,开发人员使用pci_unmap_page()或dma_unmap_page()函数。
DMA设备与Linux内核内存的I/O
转自 http://www.cnblogs.com/hanyan225/archive/2010/10/28/1863854.html
上节我们说到了dma_mem_alloc()函数,需要说明的是DMA的硬件使用总线地址而非物理地址,总线地址是从设备角度上看到的内存地址,物理地址是从CPU角度上看到的未经转换的内存地址(经过转换的那叫虚拟地址)。在PC上,对于ISA和PCI而言,总线即为物理地址,但并非每个平台都是如此。由于有时候接口总线是通过桥接电路被连接,桥接电路会将IO地址映射为不同的物理地址。例如,在PRep(PowerPC Reference Platform)系统中,物理地址0在设备端看起来是0X80000000,而0通常又被映射为虚拟地址0xC0000000,所以同一地址就具备了三重身份:物理地址0,总线地址0x80000000及虚拟地址0xC0000000,还有一些系统提供了页面映射机制,它能将任意的页面映射为连续的外设总线地址。内核提供了如下函数用于进行简单的虚拟地址/总线地址转换:
unsigned long virt_to_bus(volatile void *address)void *bus_to_virt(unsigned long address)
在使用IOMMU或反弹缓冲区的情况下,上述函数一般不会正常工作。而且,这两个函数并不建议使用。
需要说明的是设备不一定能在所有的内存地址上执行DMA操作,在这种情况下应该通过下列函数执行DMA地址掩码:int dma_set_mask(struct device *dev, u64 mask);
比如,对于只能在24位地址上执行DMA操作的设备而言,就应该调用dma_set_mask(dev, 0xffffffff).DMA映射包括两个方面的工作:分配一片DMA缓冲区;为这片缓冲区产生设备可访问的地址。结合前面所讲的,DMA映射必须考虑Cache一致性问题。
内核中提供了一下函数用于分配一个DMA一致性的内存区域:void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp)
这个函数的返回值为申请到的DMA缓冲区的虚拟地址。此外,该函数还通过参数handle返回DMA缓冲区的总线地址。与之对应的释放函数为:void dma_free_coherent(struct device *dev, size_t size, void *cpu_addr, dma_addr_t handle)
以下函数用于分配一个写合并(writecombinbing)的DMA缓冲区:void *dma_alloc_writecombine(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp)
与之对应的是释放函数:dma_free_writecombine(),它其实就是dma_free_conherent,只不过是用了#define重命名而已。
此外,Linux内核还提供了PCI设备申请DMA缓冲区的函数pci_alloc_consistent(),原型为:void *pci_alloc_consistent(struct pci_dev *dev, size_t size, dma_addr_t *dma_addrp),对应的释放函数为:void pci_free_consistent(struct pci_dev *pdev, size_t size, void *cpu_addr, dma_addr_t dma_addr)
相对于一致性DMA映射而言,流式DMA映射的接口较为复杂。对于单个已经分配的缓冲区而言,使用dma_map_single()可实现流式DMA映射:dma_addr_t dma_map_single(struct device *dev, void *buffer, size_t size, enum dma_data_direction direction),如果映射成功,返回的是总线地址,否则返回NULL.最后一个参数DMA的方向,可能取DMA_TO_DEVICE, DMA_FORM_DEVICE, DMA_BIDIRECTIONAL和DMA_NONE;
与之对应的反函数是:void dma_unmap_single(struct device *dev,dma_addr_t *dma_addrp,size_t size,enum dma_data_direction direction)
通常情况下,设备驱动不应该访问unmap()的流式DMA缓冲区,如果你说我就愿意这么做,我又说写什么呢,选择了权利,就选择了责任,对吧。这时可先使用如下函数获得DMA缓冲区的拥有权:void dma_sync_single_for_cpu(struct device *dev,dma_handle_t bus_addr, size_t size, enum dma_data_direction direction)
在驱动访问完DMA缓冲区后,应该将其所有权还给设备,通过下面的函数:void dma_sync_single_for_device(struct device *dev,dma_handle_t bus_addr, size_t size, enum dma_data_direction direction)int dma_map_device(struct device *dev,struct scatterlist *sg, int nents,enum dma_data_direction direction)
Linux系统中可以有一个相对简单的方法预先分配缓冲区,那就是同步“mem=”参数预留内存。例如,对于内存为64MB的系统,通过给其传递mem=62MB命令行参数可以使得顶部的2MB内存被预留出来作为IO内存使用,这2MB内存可以被静态映射,也可以执行ioremap().
相应的函数都介绍完了:说真的,好费劲啊,我都想放弃了,可为了小王,我继续哈..在linux设备驱动中如何操作呢:
像使用中断一样,在使用DMA之前,设备驱动程序需要首先向系统申请DMA通道,申请DMA通道的函数如下:int request_dma(unsigned int dmanr, const char * device_id)同样的,设备结构体指针可作为传入device_id的最佳参数。
使用完DMA通道后,应该使用如下函数释放该通道:void free_dma(unsinged int dmanr)
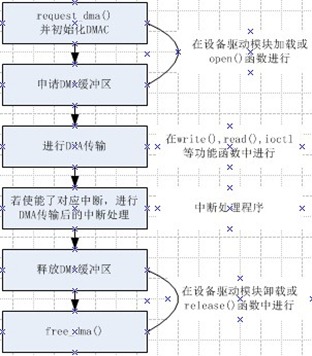
作为本篇的最后,也作为Linux设备驱动核心理论的结束篇,总结一下在Linux设备驱动中DMA相关代码的流程。如下所示: